1. Основные направления исследований
в области искусственного интеллекта
2. Структура
интеллектуальной ИС
3. Модели
представления знаний
6. Классы
систем Data Mining.
Примеры нейросетевых систем.
7. Нейроны
и нейросети. Предмет и методы нейробиологии. Формальный нейрон.
9. Процесс
обучения в нейронных сетях.
10. Различие
экспертных и нейросетевых систем по характеру знаний.
11. Многослойный
персептрон. Звезды Гроссберга
13. Классификация
задач экспертных систем и эвристическая классификация.
14. –
15 Интеллектуальные роботы.
17. 16
Рассуждения, основанные на прецедентах.
18. Извлечение
и адаптация прецедентов.
19. Инструментарий
конкурентной разведки.
21. Классификация
методов извлечения знаний.
1.
Основные направления исследований в области
искусственного интеллекта
Искусственный
интеллект
– одно из направлений информатики, связанное с разработкой
программно-аппаратных средств для решения
интеллектуальных задач, связанных с выбором и принятием решений, традиционно
присущих человеку. Среди множества направлений искусственного интеллекта есть
несколько ведущих, которые в настоящее время вызывают наибольший интерес у
исследователей и практиков:
1) Представление знаний и разработка систем,
основанных на знаниях (knowledge-based systems)
Направление связано с разработкой моделей
представления знаний, созданием баз знаний, образующих ядро экспертных систем.
В последнее время включает в себя модели и методы извлечения и структурирования
знаний и сливается с инженерией знаний.
2) Программное обеспечение систем ИИ (software engineering for Al)
В рамках этого направления разрабатываются специальные
языки для решения интеллектуальных задач, в которых традиционно упор делается
на преобладание логической и символьной обработки над вычислительными
процедурами.
3) Разработка естественно-языковых интерфейсов и
машинный перевод (natural language processing)
В настоящее время используется следующие модели:
• применение так называемых "языков-посредников" или языков смысла, в результате происходит
дополнительная трансляция «исходный язык оригинала — язык смысла — язык
перевода»;
• ассоциативный
поиск аналогичных фрагментов текста и их переводов в специальных текстовых репозиториях или базах данных;
• структурный
подход, включающий последовательный анализ и синтез естественно-языковых
сообщений. Традиционно такой подход предполагает наличие нескольких фаз
анализа:
1. Морфологический
анализ — анализ слов в тексте.
2. Синтаксический
анализ — разбор состава предложений и грамматических связей между словами.
3. Семантический
анализ — анализ смысла составных частей каждого предложения на основе
некоторой предметно-ориентированной базы знаний.
4. Прагматический
анализ — анализ смысла предложений в реальном контексте на основе
собственной базы знаний. Синтез ЕЯ-сообщений
включает аналогичные этапы, но несколько в другом порядке.
4) Интеллектуальные роботы (robotics)
Роботы — это
электротехнические устройства, предназначенные для автоматизации человеческого
труда. Можно условно выделить несколько поколений в истории создания и развития
робототехники:
I Роботы с
жесткой схемой управления.
Практически все современные промышленные роботы принадлежат к первому
поколению. Фактически это программируемые манипуляторы.
II Адаптивные
роботы с сенсорными устройствами.
Есть образцы таких роботов, но в промышленности они пока используются мало.
III Самоорганизующиеся
или интеллектуальные роботы. Это — конечная цель развития робототехники.
Основные нерешенные проблемы при создании интеллектуальных роботов — проблема
машинного зрения и адекватного хранения и обработки трехмерной визуальной
информации.
5) Обучение и самообучение (machine
learning)
Включает модели, методы и алгоритмы, ориентированные
на автоматическое накопление и формирование знаний на основе анализа и
обобщения данных. Включает обучение по примерам (или
индуктивное), а также традиционные подходы из теории распознавания образов.
6) Распознавание образов (pattern
recognition)
Основной подход — описание классов объектов через определенные значения значимых признаков.
Каждому объекту ставится в соответствие матрица признаков, по которой
происходит его распознавание. Процедура распознавания использует чаще всего
специальные математические процедуры и функции, разделяющие объекты на классы.
7) Новые архитектуры компьютеров (new hardware platforms and architectures)
8) Игры и машинное творчество
9) Другие направления
Генетические алгоритмы; когнитивное моделирование; интеллектуальные
интерфейсы; распознавание и синтез речи; дедуктивные модели (многоагентные системы; онтологии; менеджмент знаний; логический
вывод; формальные модели; мягкие вычисления и многое другое).
2.
Структура интеллектуальной ИС
Структура ИИС
должна обязательно включать следующие три комплекса вычислительных средств:
1.
исполнительная
система
– это совокупность средств, обеспечивающих выполнение сформированной программы,
спроектированных с позиций эффективного решения задач, имеет в ряде случаев
проблемную ориентацию;
2.
интеллектуальный
интерфейс -
система программных и аппаратных средств, обеспечивающих для конечного
пользователя использование компьютера для решения задач, которые возникают в
среде его профессиональной деятельности либо без посредников
либо с незначительной их помощью. Это совокупность средств интеллектуального
интерфейса, имеющих гибкую структуру, которая обеспечивает возможность
адаптации в широком спектре интересов конечных пользователей.
3.
база знаний (БЗ) —
информационная база, обеспечивающая использование вычислительными средствами
первых двух комплексов целостной и независимой от обрабатывающих программ
системы знаний о проблемной среде. База знаний занимает центральное положение по
отношению к остальным компонентам вычислительной системы в целом, через БЗ
осуществляется интеграция средств ВС, участвующих в
решении задач. База знаний, отражает опыт конкретных людей, групп, обществ,
человечества в целом, в решении творческих задач в выделенных сферах
деятельности, традиционно считавшихся прерогативой интеллекта человека.

Наличие
вышеперечисленных комплексов является обязательным, чтобы ИС могла бы
называться интеллектуальной ИС. В общем виде схематическое изображение СИИ представлено на рисунке
Виды
интеллектуальных ИС (информационных систем)
- интеллектуальные информационно-поисковые системы (системы типа
«вопрос — ответ»), которые в процессе диалога обеспечивают взаимодействие
конечных пользователей-непрограммистов с базами данных и знаний
профессиональными языками пользователей, близких к
естественных;
- расчетно-логические системы, которые дают
возможность конечным пользователям, которые не являются программистами и
специалистами в области прикладной математики, решать в режиме диалога с ЭВМ
свои задачи с использованием сложных методов и соответствующих прикладных
программ;
- нейронные сети и "размытые" ( fuzzy ) логики;
- естественно-языковые системы;
- экспертные системы (ЭИС), которые дают
возможность проводить эффективную компьютеризацию сфер, где знания могут быть
представлены в экспертной описательной форме, но использования математических
моделей осложненное или невозможное.
3.
Модели представления знаний
Знания –
закономерности предметной области (законы, принципы), полученные на практике
либо вытекающие из теории, описывающей предметную область.
Знания – это
метаданные.
Формы знаний:
1. знания в памяти человека;
2. знания на материальных носителях;
3. поле знаний, т.е. условное описание
объектов предметной области и их связей
4. знания, представленные на спец. языке;
5. база знаний на машинных носителях.
Выделяют знания:
1. поверхностные, которые описывают
видимые связи между событиями и фактами предметной области;
2. глубинные, которые
отражают структуру процессов, протекающих в предметной
области и могут использоваться для прогнозирования изменения состояния
объекта.
Различают
следующие модели представления знаний:
1. формальная логическая модель. Знания
представлены в виде предикатов, устанавливающих логические связи между объектами
предметной области.
2. продукционная модель, где знания
представлены в виде правил: Если (условие) то (действие).
3. семантическая сеть. Знания представлены
в виде графа. Узлы графа - объекты предметной области, а рёбра – отношения.
4. фреймовая модель. Знания представлены в
виде абстрактного описания типов объектов, процессов и явлений.
4.
Технологии Text Mining и Data Mining. Задачи, основные виды технологий, требования к
исходным данным.
В последнее
время широкое распространение получили технологии Text
Mining и Data Mining. Они являются направлением т.н. контекст - анализа.
Эти технологии предполагают автоматическое выявление из текстовых массивов
нового смысла, новых данных, знаний.
Задача Text Mining – выбрать
ключевую и наиболее значимую информацию для пользователя.
Text Mining
позволяет анализировать большие V инфы в поисках тенденций, шаблонов и в/связей, способных
помочь принятию решений. Т.о, Text Mining – это новый вид поиска, который в отличии от традиционных подходов не только находит списки
документов, релевантных запросу, но и позволяет получить ответ на просьбу:
«Помогите мне понять смысл, разобраться с этой проблемой».
Выделяют 4
основных вида приложений технологий Text Mining:
1. Классификация
текста. В неё используются правила для размещения документов в определённой
категории;
2. Кластеризация
базируется на признаках документов. Также разделяет документы на категории, но
без применения предопределённых категорий;
3. Построение
семантической сети или анализ связей, который определяет появление дескрипторов
(ключевых фраз) в документе для обеспечения поиска и навигации;
4. Извлечение
фактов. Цели – получение некоторых фактов из текста, с целью улучшения
классификации поиска и кластеризации.
Технологии Text Mining
используются для решения задач: автореферирования, прогнозирования, нахождения исключений,
ответы на вопросы и т.д.
Прогнозирование состоит в том, чтобы
предсказать по значениям одних признаков объекта значения других.
Нахождение исключений – это задача
поиска объектов, которые по своим характеристикам сильно выделяются из общей
массы.
Data Mining буквально
переводится как добыча данных. Деятельность любого предприятия сейчас
сопровождается регистрацией и записью всех подробностей его деятельности.
Специфика требований к обработке таких данных такова:
1. данные имеют
неограниченный объем;
2. данные
являются разнородными (по количественным, качественным характеристикам);
3. результаты дб конкретны и понятны;
4. инструмент
для обработки «сырых» данных дб просты в
использовании.
технология «сверху - вниз»
↓ поверхностный -
язык простых запросов (SQL-запрос)
неглубокий -оперативная аналитическая обработка (OLAP)
↑ скрытый -
«раскопка» данных (Data
Mining)
технология «снизу - вверх»
Рисунок – Уровни знаний, извлекаемые из знаний
5.
Технологии Text Mining и Data Mining. Сферы применения Text Mining и Data Mining. Закономерности, которые выявляются методами Text Mining и Data Mining. Приложения Data Mining.
Сфера применения Data Mining. Data Mining
м применяться везде, где имеются какие-либо данные. В 1-ую очередь
методы Data Mining
применяются в крупных коммерческих предприятиях, которые развёртывают проекты
на основе хранилищ данных.
Приложения на
основе Data Mining
охватывают → сферы деятельности:
1. розничной
торговли;
2. банковское
дело (например, выявление мошенничества с кредитными картами);
3.
телекоммуникации;
4. страхование;
5. медицина.
Выделяют 4
основных вида приложений технологий Text Mining:
1. Классификация
текста. В неё используются правила для размещения документов в определённой
категории;
2. Кластеризация
базируется на признаках документов. Также разделяет документы на категории, но
без применения предопределённых категорий;
3. Построение
семантической сети или анализ связей, который определяет появление дескрипторов
(ключевых фраз) в документе для обеспечения поиска и навигации;
4. Извлечение
фактов. Цели – получение некоторых фактов из текста, с целью улучшения
классификации поиска и кластеризации.
6.
Классы систем Data Mining. Примеры нейросетевых
систем.
DM является мультидисциплинарной
областью, возникшей и развивающейся на базе достижений прикладной статистики
распознавания образов, методов искусственного интеллекта, теории БД и т.д.
Отсюда обилие методов и алгоритмов, реализованных в различных действительных системах
DM.
1.
Предметно-ориентированная
аналитическая система.
Эти системы
очень разнообразны. Наиболее широкий подкласс таких систем, получивший
распространение в области исследования финансовых рынков, носит название
технический анализ. Он представляет собой совокупность нескольких десятков
методов прогноза динамики цен и выбора оптимальной структуры инвестиционного
портфеля.
2.
Статистические
пакеты.
Последняя версия
статистических пакетов уже включают в себя DM.
Недостатком этих систем является требование к специально подготовленному
пользователю и дороговизна (1000-15000$). Пример: компания SAS, SPSS, StatGraphics, Statistica, Stadio.
3.
Нейронные
сети.
Нейронная сеть –
большой класс систем, архитектура которых имеет аналогию с построением нервной
ткани из нейронов. На нейроны нижнего слоя подаются значения входных
параметров, на основе которых нужно принимать какие-то решения, прогнозировать
развитие ситуации. Эти значения рассматриваются как сигналы, передающиеся в
следующий слой, ослабляясь или усиливаясь в зависимости от числовых значений
весов, приписанным межнейронным связям. В результате нейроны на выходе самого
верхнего слоя вырабатывают некоторое значение, которое рассматривается как
ответная реакция всей сети на введенные значения входных параметров.
Для того, чтобы сеть применять в дальнейшем ее необходимо обучить на
основе полученных ранее данных. Стоимость нейросетей
– 1500-8000$. Примеры: BrainMaker, NeyroShall, OWA.
7.
Нейроны и нейросети. Предмет и методы нейробиологии.
Формальный нейрон.
Элементом клеточной структуры мозга является нервное окончание. Нейрон выполняет прием, элементарные преобразования, дальнейшую передачу информации другим нейронам. Информация переносится в виде импульса нервной активности, имеющей электрохимическую природу.
Взаимодействующие между собой посредством передачи через отростки возбуждений нейроны формируют нейронные сети. Общее число нейронов в центральной нервной системе человека достигает 1010 - 1011, при этом каждая нервная клетка связана в среднем с 103 - 104 других нейронов. Установлено, что в головном мозге совокупность нейронов в объеме масштаба 1 мм3формирует относительно независимую локальную сеть, несущую определенную функциональную нагрузку.
|
|
|
|
Рисунок –
Структура простой нейронной сети |
Рисунок –
Общая схема строения нейрона |


К предмету нейробилологии относится изучение нервной системы и ее главного органа - мозга. Принципиальным вопросом для этой науки является выяснение соотношения между строением нервной системы и ее функцией. При этом рассмотрение проводится на на нескольких уровнях: молекулярном, клеточном, на уровне отдельного органа, организма в целом, и далее на уровне социальной группы. Таким образом, классический нейробилогический подход состоит в последовательном продвижении от элементарных форм в направлении их усложнения.
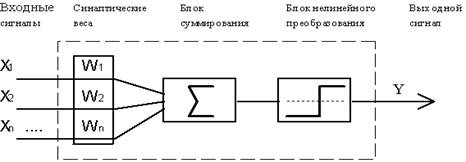
Формальный
нейрон. Исторически первой работой, заложившей теоретический фундамент для
создания искусственных моделей нейронов и нейронных сетей, принято считать
опубликованную в
С
современной точки зрения, формальный нейрон представляет собой математическую
модель простого процессора, имеющего несколько входов и один выход. Вектор
входных сигналов (поступающих через "дендриды")
преобразуется нейроном в выходной сигнал (распространяющийся по
"аксону") с использованием трех функциональных блоков: локальной
памяти, блока суммирования и блока нелинейного преобразования.
8.
Персептрон Розенблатта.
Одной из первых
искусственных сетей, способных к перцепции (восприятию) и формированию реакции
на воспринятый стимул, явился PERCEPTRON Розенблатта.
Персептрон рассматривался его автором не как конкретное техническое
вычислительное устройство, а как модель работы мозга.

Рисунок -
Элементарный персептрон Розенблатта
Простейший
классический персептрон содержит нейроподобные
элементы трех типов:
- S-элементы
формируют сетчатку сенсорных клеток, принимающих двоичные сигналы от внешнего
мира.
- А-элементы –
ассоциативные (формальные нейроны), выполняют нелинейную обработку информации и
имеют изменяемые веса связей.
- R-элементы с фиксированными весами формируют сигнал реакции персептрона на входной стимул.
Розенблатт называл такую нейронную сеть трехслойной, однако
по современной терминологии представленная сеть обычно называется однослойной,
так как имеет только один слой нейропроцессорных
элементов. Однослойный персептрон характеризуется матрицей синаптических связей W от S- к A-элементам. Элемент матрицы
![]() отвечает связи,
ведущей от i-го S-элемента к j-му A-элементу. С
сегодняшних позиций однослойный персептрон представляет скорее исторический
интерес, однако на его примере могут быть изучены основные понятия и простые
алгоритмы обучения нейронных сетей.
отвечает связи,
ведущей от i-го S-элемента к j-му A-элементу. С
сегодняшних позиций однослойный персептрон представляет скорее исторический
интерес, однако на его примере могут быть изучены основные понятия и простые
алгоритмы обучения нейронных сетей.
9.
Процесс обучения в нейронных сетях.
Общая проблема
кибернетики, заключающаяся в построении искусственной системы с заданным
функциональным поведением в контексте нейронных сетей, формируется →
образом: необходимо синтезировать требуемую искусственную сеть. Данная задача м включать в себя → подзадачи:
1. выбор
существенных для решаемой задачи признаков и формирование пространства
признаков;
2. выбор и
разработка архитектуры нейронной сети, адекватной решаемой задачи;
3. получение
обучающей выборки из наиболее представительных, по мнению эксперта, признаков
пространства;
4. обучение
нейронной сети на обучающей выборке.
В случае когда задачей нейронной сети является отнесение
входных наборов признаков к одной из заданных групп, говорят, что нейросетевая система выполняет классификацию или
категоризацию данных. Пример, классификация химических веществ.
Проблема
категоризации находится на ступеньку выше по сложности в сравнении с
классификацией. Особенность её заключается в том, что помимо отнесения образа к
какой-либо группе → определить сами эти группы.
10.
Различие экспертных и нейросетевых систем по характеру знаний.
1. Источник
знаний
ЭС: источник
знаний – это формализованный опыт эксперта, выраженный в виде логических
утверждений – правил и фактов, понимаемых системой
безусловно.
Нейросетевые системы: совокупный
опыт эксперта + индивидуальный опыт обучающейся нейронной сети.
2. Характер
знаний
ЭС: это формально-логическая, левополушароное
знание в виде правил.
Нейросетевые системы: это
ассоциативное правополушарное знание в виде связей между нейросетевой
системой.
3. Развитие
знаний
ЭС: в форме
расширения совокупности фактов и правил (БЗ).
Нейросетевые системы: в форме дообучения на дополнительной последовательности примеров с
уточнением границ категорий и формированием новых категорий.
4. Роль
эксперта
ЭС: задаёт на
основе правил полный V
знаний ЭС.
Нейросетевые системы: отбирает
характерные примеры для обучающей выборки, определяет признаки, которые б
являться входными данными для нейросети.
5. Роль
искусственной системы
ЭС: это поиск
цепочки фактов и правил для доказательства суждений.
Нейросетевые системы: формирование
индивидуального опыта в форме категорий, получаемых на основе примеров.
Различия в
характере ЭС и нейросетевые системы обуславливает и
различия в сферах их применения. ЭС применяются в узких предметных областях с
хорошо структурированными знаниями. Нейросеть
применяется также с задачах с плохо структурированной инфой. Например, при распознавании образов, рукописного
текста, анализ речи и т.д.
11.
Многослойный персептрон. Звезды Гроссберга
Рассмотрим
иерархическую сетевую структуру, в которой связанные между собой нейроны
объединены в несколько слоёв. На возможность построения таких архитектур указал
ещё Розенблатт.
Межнейронные семантические связи устроены
т.о., что каждый нейрон на данном уровне иерархии принимает и обрабатывает
сигналы от каждого нейрона более низкого уровня.
(рисунок)
Звёзды Гроссберга. Эти архитектуры состоят из нейронов в
форме звезды. Они различаются на входные
и выходные звёзды.
Входная имеет n входов и 1 выход
Выходная имеет множество
выходов и 1 вход
Особенностью
нейронов в форме звёзд Гроссберга является
локальность памяти. Каждый нейрон в форме входной звезды помнит свой
относящийся к нему образ и игнорирует остальные. Каждый выходной звезде
присуща также конкретная командная функция. Область памяти связывается с
определённым нейроном, а не возникает в → в/д множества нейронов в сети.
12.
Нейронные сети с обратными связями. Алгоритмы разобучения нейросетей. Компьютерное
моделирование нейросетей.
Рассмотренные
ранее персептроны относятся к классу сетей с направленным потоком
распространения инфы и не содержат обратных связей.
В общем случае мб рассмотрена нейросеть,
содержащая произвольные обратные связи.
Без обратной
связи:
С обратной
связью
Недостаток –
неустойчивость нейросети.
Алгоритмы разобучени. Возможность забывания ненужной
(лишней) инфы является одним из отличительных свойств
биологической памяти. Идея этого свойства проста: При запоминании образов обучающей выборке вместе с ними запоминаются и
ложные образы, их-то и следует забыть.
Соответствующие
алгоритмы получили название алгоритмы разобучения.
Сначала работают алгоритмы с обучением сети, а потом для устранения ложных
образов выполняются алгоритмы разобучения.
Компьютерное
моделирование нейросетей.
Значительная
доля всех приложений нейросетей приходится на
использование их программных модулей, обычно называющихся нейроимитаторами.
Разработка программы стоит дешевле, а получаемый продукт представляется более
наглядным, мобильным и удобным, нежели специализированная аппаратура. В любом
случае, разработке аппаратной реализации нейросети
всегда д предшествовать её всесторонняя обработка на
основе теории с использованием компьютерной модели.
Нейроимитатор д выполнять → функции:
1. описание и
формирование архитектуры нейросетей;
2. сбор данных
для обучающей выборки;
3.
обучение выбранной нейросети на обучающей выборке;
4. тестирование обученной нейросети;
5. визуализация
процесса обучения и тестирования;
6. решение задач
обученной сетью.
Решение задач с применением нейросети м состоять из → этапов: постановка
задачи в терминах нейросети и выбор, и анализ нейроархитектуры, адекватной задаче.
13.
Классификация задач экспертных систем и
эвристическая классификация.
Хейес предложил классификацию ЭС, которая отражает специфику задач при помощи технологии эвристической классификации.
1. Интерпретирующие системы – предназначены для формирования описания ситуаций по результатам наблюдений или данным, полученным от различного рода сенсоров. Типичная задача, которая решается этими системами – распознавание образов, определение химической структуры вещества и т.д.
2. Прогнозирующие системы – предназначены для логического анализа возможных последствий заданных ситуаций или событий. Типичные задачи: предсказание погоды, прогноз ситуаций на финансовых рынках и т.д.
3. Диагностические системы – предназначены для обнаружения источников неисправностей по результатам наблюдений за поведением контролируемой системы. Типичные задачи: диагностика в различных областях (медицина, механика, электроника).
4. Системы планирования – предназначены для подготовки планов проведения последовательных операций, приводящих к заданной цели. Задачи – планирование поведения роботов, составление маршрутов передвижения транспорта.
5. Системы проектирования – предназначены для структурного синтеза конфигурации объектов при заданных отношениях (синтез электрических схем, компоновка архитекторских планов, оптимальное размещение объектов в ограниченном пространстве).
6. Системы мониторинга – анализирует поведение контролируемых систем и, сравнивая полученные данные с критическими точками, заранее составляет план, прогнозирует вероятность достижения поставленной цели (контроль движения воздушного транспорта, наблюдение за состоянием энергетических объектов).
7. Наладочные системы – помогают программистам в наладке кода программного продукта, сюда же относятся и консультирующие системы.
8. Системы оказания помощи при ремонте оборудования – выполняют планирование процесса, устранение неисправностей в сложных объектах, например, в сетях инженерных коммуникаций.
9. Обучающие системы – проводят анализ знаний студентов по определенному предмету, отыскивают пробелы в знаниях и предлагают средства их ликвидации.
10. Системы контроля – обеспечивают адаптивное управление поведением сложных человеко-машинных систем, прогнозируя появление возможных сбоев и планируя действия, необходимые для их устранения.
Кленси предложил альтернативный метод классификации систем, взяв за основу набор рядовых операций, выполняемых в рассмотренной системе. Он предложил разделить синтетические операции, результатом которых являлись изменения структуры системы и аналитические операции, которые интерпретировали характеристики и свойства системы, не изменяя ее как таковую. Эта обобщенная концепция м.б. конкретизирована, в результате чего построена иерархическая схема видов операций.


Суть
эвристической классификации состоит в установлении иерархических
ассоциативных связей между данными и категориями классификации, которые требуют
выполнения промежуточных логических заключений.
На следующем
рисунке показаны основные этапы выполнения эвристической классификации:

14.
– 15 Интеллектуальные роботы.
Успехи в
развитии средств вычислительной техники обусловили преимущественное внимание к
исследованиям в области машинного интеллекта. Результаты этих исследований
широко освещены в научных и научно-популярных изданиях. Рассмотрим значение их
для решения проблем, связанных с созданием и использованием интеллектуальных
роботов.
Планирование. Практически
одновременно с появлением ЭВМ первого поколения в ИИ начали разрабатывать
программы, решающие головоломки, играющие в различные игры и доказывающие
теоремы. Для робототехники особую роль сыграло развитие теории и техники
автоматического доказательства теорем, в частности разработка
машинно-ориентированной предикативной логики.
Наиболее
известной системой планирования, использующей технику доказательств, является
система STRIPS, разработанная для управления действиями
самоходного аппарата-робота. Этот робот мог передвигаться в комнатах, подходить
к имеющимся объектам, толкать их, проходить через двери и т.п. Составляемые
системой планы состоят из шести действий. Созданная в 1971 г. система оказала
значительное влияние на дальнейшее развитие работ в данной области.
Машинное зрение. Особое внимание
в исследованиях по машинному интеллекту уделяется проблеме распознавания
образов. Наиболее развитыми в робототехнике являются методы распознавания
зрительных образов. Алгоритмы, реализующие эти методы, являются основной частью
систем машинного, или технического, зрения (СТЗ). Источником информации для них
являются различные оптические системы, видеокамеры и т. п.
Основные задачи,
решаемые СТЗ, можно разделить на два класса:
инспекцию и
идентификацию.
Задачи инспекции заключаются в проверке наличия объектов, обнаружении дефектов
и т. п. Типичными задачами идентификации являются определение позиций известных
объектов, выделение отдельных объектов в случаях, когда они соприкасаются,
перекрываются или лежат “навалом”, определение похожести объектов и т. п.
Кроме зрительной
информации в робототехнических системах используют и другие ее виды: тактильную
(о соприкосновении), проксимитную (о расстоянии),
позиционную (о положении), силовую и моментную. Источниками информации являются
специально разрабатываемые датчики: дальномеры, тензомеры,
ультразвуковые локаторы. Обрабатывается она системами, которые строят модели
внешних ситуаций робота или его внутренних состояний. Некоторые из таких систем
имеют чисто измерительную природу, другие используют развитые средства
распознавания образов.
Речевое общение. Работы в этой
области группируются вокруг задач автоматического перевода, реферирования
текстов, построения справочных и информационно-поисковых устройств и, наконец,
удобных языков общения человека с машиной. Последняя задача в настоящее время
привлекает наибольшее внимание, ибо ее решение позволило бы кардинальным
образом изменить характер использования ЭВМ специалистами, работающими в
предметных областях и не владеющими языками и навыками программирования.
Необходимость в таком изменении остро назрела в связи с процессами компьютеризации
науки, образования и народного хозяйства в целом.
Системы речевого
общения используются при создании роботов класса Р,
получивших название роботов связи. Такие роботы могут входить также в состав
интегральных роботов.
Для
робототехники наибольший интерес представляют анализаторы речи, которые
используются в составе диалогового процессора для ввода в систему управления
робота устных команд и сообщений.
Программирование
роботов.
Языки управления роботами строятся по тем же принципам, что и обычные
алгоритмические языки высокого уровня, и отличаются лишь возможностью полнее
учитывать специфику задач управления роботами, особенности их структуры и т. п.
При использовании таких языков диалоговый процессор может быть представлен ЭВМ,
осуществляющей интерпретацию поступающих на нее команд. Языки программирования
роботов разделяют на три основных уровня.
Языки первого
уровня
содержат команды, явно задающие необходимые движения робота. Интерпретируя эти
команды, диалоговый процессор адресует их непосредственно “жесткому” уровню
управления. При программировании робота на языках второго уровня
пользователь определяет взаимосвязь того, что робот должен будет делать, с тем,
что он в это время будет воспринимать. В данном случае диалоговый процессор
передает команды некоему решателю, который реализуется, как правило, в
виде программной системы. Языки третьего уровня дают возможность
пользователю программировать действия робота путем указания желаемого эффекта
их воздействия на объект. При этом оказывается необходимым наличие в системе
управления планировщика, работа которого может быть основана, например, на
технике доказательства теорем.
17.
16 Рассуждения, основанные на прецедентах.
Существует
множество рутинных задач, выполняемых человеком, которые не поддаются четкой
логике. Человек сознательно или подсознательно часто не выполняет логический
анализ и эвристический поиск. Человеку всегда приходит на помощь память и
прежний опыт. Проще распознать ситуацию и найти для нее аналог, чем заново
формировать решение, но воспоминания и приобретенный опыт трудно свести к
набору правил. Гораздо проще представить некоторую библиотеку ситуаций,
встречавшихся в прошлом, которые имеют отношение к возникшей проблеме.
Подход к
принятию решений с использованием знаний, полученных ранее по аналогиис имеющей место ситуацией, получил название
рассуждений, основаных на прецедентах (case based
reasoning).
Прецеденты
содержат определенную специфическую информацию, вставленную в некоторый
контекст. Содержимое прецедентов – это знания, а контекст описывает состояния
внешнего мира, в которых эти знания применяются. Прецедент должен содержать
знания в такой форме, которая может быть воспринята программой.
Прецедент должен
представлять решение проблемы в определенном контексте и описывать то состояние
мира, которое получится, если будет принято предлагаемое в нем решение.
Прецедент
реализуется в виде фрейма, в котором структурирована информация о проблеме,
решение и контекст.
Рассмотрим
систему для формирования кулинарных рецептов CHEF.
Исходные данные:
информация о целевых характеристиках блюда. Выходные данные: подходящий рецепт
и последовательность операций, позволяющих получить данное блюдо.
Получив заказ,
программа просматривает свою базу прецедентов, отыскивая рецепт приготовления
аналогичного блюда, и адаптирует его с учетом особенностей текущего заказа.
После выполнения всех необходимых коррекций новый рецепт записывается в модуль
базы прецедентов.

18.
Извлечение и адаптация прецедентов.
В системах
формирования суждений на основе прецедентов используются разные схемы
извлечения прецедентов и их адаптации к новым проблемам.
В таких
программах, как CHEF, сопоставляются описания имеющихся прецедентов и
полученная спецификация цели, причем в качестве основного средства
сопоставления выступает семантическая сеть. Модуль извлечения использует эту
информацию для вычисления оценки степени близости прецедента и целевой
спецификации, а модуль модификации использует эту же информацию для подстановки
в рецепт одного ингредиента вместо другого.
Сложность поиска
решения и выявления различий между прецедентами в значительной степени зависит
от используемых термов индексации. По сути, прецеденты в базе прецедентов
конкурируют, пытаясь "привлечь" к себе внимание модуля извлечения, точно
так же, как порождающие правила конкурируют за доступ к интерпретатору. В обоих
случаях необходимо использовать какую-то стратегию разрешения конфликтов. С
этой точки зрения прецеденты должны обладать какими-то свойствами, которые, с
одной стороны, связывают прецедент с определенными классами проблем, а с другой
— позволяют отличить определенный прецедент от его "конкурентов".
Например, в программе CHEF прецеденты индексируются по таким атрибутам, как
основной ингредиент блюда, гарнир, способ приготовления и т.п., которые
специфицируются в заказе.
Одним из
популярных методов эффективного индексирования является использование
разделяемой сети свойств (shared feature
network). При этом прецеденты, у которых какие-либо
свойства совпадают, включаются в один кластер, в результате чего формируется
таксономия типов прецедентов. Сопоставление в такой разделяемой сети свойств
выполняется с помощью алгоритма поиска в ширину без обратного прослеживания.
Поэтому время поиска связано с объемом пространства логарифмической
зависимостью. Индивидуальное сопоставление, как правило, выполняется следующим
образом. Каждому свойству (или размерности) присваивается определенный вес,
соответствующий степени "важности" этого свойства. Алгоритм
сопоставления прецедентов, представленный ниже.
1. Присвоить MATCH = 0.0;
Для каждого свойства в
исходной спецификации
{
2. Найти соответственное
свойство в хранимых прецедентах.
3. Сравнить два значения и
вычислить степень близости т.
4. Умножить эту оценку на
вес свойства с.
5. Присвоить MATCH = MATCH + c*т.
}
Возвратить MATCH.
Базовая
процедура называется сопоставлением с ближайшим соседом (Nearest-Neighbor
matching), поскольку прецеденты, которые имеют
близкие значения свойств, и концептуально ближе друг другу. Это может найти
отражение и в структуре сети, где степень близости прецедентов будет
соответствовать близости их свойств.
Вычисленное по
этому алгоритму значение MATCH обычно называется агрегированной оценкой
совпадения (aggregate match
score). Естественно, что из базы прецедентов
выбирается тот, который "заслужил" самую высокую оценку. Если же
алгоритм работы системы предполагает и исследование альтернативных прецедентов,
то оставшиеся должны быть ранжированы по полученным оценкам.
Для адаптации
найденного прецедента к текущим целевым данным программы также используют
разные методы. В большинстве случаев можно обойтись заменой некоторых
компонентов в имеющемся решении или изменением порядка операций в плане. Но
существуют и другие подходы, которые перечислены ниже.
-
Повторная
конкретизация переменных в существующем прецеденте и присвоение им новых
значений.
-
Уточнение
параметров. Некоторые прецеденты могут содержать числовые значения, например
время выполнения какого-либо этапа плана. Это значение должно быть уточнено в
соответствии с новым значением другого свойства.
-
Поиск
в памяти. Иногда требуется найти способ преодоления затруднения, возникшего как
побочный эффект замены одних компонентов решения другими.
19.
Инструментарий конкурентной разведки.
Конкурентная разведка (КР) (competitive intelligence) заключается в
сборе и аналитической обработке информации, необходимой для принятия
оптимальных управленческих решений руководством высшего звена компаний при
ведении конкурентной борьбы. Система конкурентной разведки (СКР) должна позволять
руководству, а также аналитическому и маркетинговому отделам компании не только
оперативно реагировать на изменения ситуации на рынках, но и оценивать
дальнейшие возможности своего развития. Основная цель СКР — переход от
традиционного метода интуитивного принятия решений на основе недостаточной
информации к управлению, основанному на знаниях.
КР в современных условиях выполняется для достижения
двух основных целей — снижение
рисков и обеспечение безопасности сделок, а также приобретение конкурентных преимуществ.
Современная СКР должна позволять не только осуществлять мониторинг информации,
но и моделировать стратегию конкурентов, выявить их партнеров, поставщиков,
уяснить условия их сотрудничества. Основные задачи СКР относятся к нахождению и
обобщению информации о следующих объектах:
-
Партнеры,
акционеры, смежники, союзники, контрагенты, клиенты, конкуренты (личности и
компании).
-
Объединения
компаний, слияния, поглощения, кризисные ситуации и т.п.
-
Кадровый
состав как своей компании, так и партнеров, конкурентов
и т.д., его изменения и динамика.
-
Торговый
оборот, бюджет и его распределения по пунктам.
-
Заключенные
договора, достигнутые соглашения или договоренности.
Интерес при проведении КР вызывает не только
непосредственная сфера деятельности компаний, но и сферы их влияния и
интересов. Эти знания могут применяться, например, для оказания влияния на
позиции партнеров и оппонентов в ходе деловых переговоров. При этом, в отличие от промышленного шпионажа, КР проводится строго
в рамках правовых норм.
Сегодня для КР основными источниками информации служат Internet,
пресса, а также открытые БД. Очень популярны среди специалистов по КР БД
государственных и статистических органов, торгово-промышленных палат, органов
приватизации и т.д. Большую пользу приносят и отдельные
доступные БД других органов власти (в России: Интегрум, Лабиринт).
Традиционно КР опирается на следующие источники
информации: опубликованные документы открытого доступа; сведения, находящиеся в
документах, уже имеющихся в компаниях, ведущих КР, результаты маркетинговых
исследований, информация, полученная на конференциях, при общении с клиентами и
коллегами. Большая часть этих данных попадает в сетевую прессу, пресс-релизы
или публикуется на корпоративных Web-сайтах.
Как правило, для успешного ведения КР должен быть
создан и непрерывно поддерживаться банк данных, включающий следующие основные
БД:
-
конкуренты
(действующие и потенциальные);
-
информация
о рынке (тенденции, номенклатурная, ценовая, адресная информация);
-
технологии
(продукты, выставки, конференции, ГОСТы, качество);
-
ресурсы
(сырье, человеческие и информационные ресурсы);
-
законодат-во (междунар-е, центр-е,
региональные и ведомственные нормативно-правовые акты);
-
общие
тенденции — политика, экономика, региональные особенности, социология, демография.
СКР, использующая Internet
как один из источников информации,
должна настраиваться под специфику деятельности компании. Она должна включать в
себя соответствующую классификацию, гибкие механизмы поиска, оперативной
доставки данных, а также качественной оценки информации. Одной из самых важных
задач анализа информации является определение ее достоверности, т.е. задача
анализа и фильтрации шума и ложной информации. Без таких оценок всегда есть
риск принять неверные решения. После анализа достоверности информации должны
следовать оценки ее точности и важности. Главным критерием достоверности данных
на практике является подтверждение информации другими источниками,
заслуживающими доверия.
Но, кроме доступных через традиционные
ИПС Web-страниц, существует скрытый Web. Это, прежде
всего, динамически генерируемые страницы, файлы разнообразных форматов,
информация из многочисленных баз данных, которые представляют собой самый
большой интерес для КР. К разряду "скрытого" Web
относятся следующие системы:
- он-лайновая информационная
система Lexis-Nexis;
-
сервис Auto TrackXP корпорации ChoicePoint
Процесс КР можно рассматривать как построение сети
из исследуемых объектов и связей между ними. Результаты должны представлять
собой аналитическую информацию, которая может быть использована для ПР.
Сегодня решать задачи КР на основе информации из Internet помогают общедоступные и специальные
программы и сервисы. Например, в последнее время приобрели популярность так называемые "персонализированные разведпорталы",
способные отбирать информацию по самым узким, специфическим вопросам и темам и
предоставлять ее заказчикам. В настоящее время декларированы технологии и
системы "компьютерной КР", идея которых заключается в автоматизации и
ускорении процессов извлечения необходимой для конкурентной борьбы информации
из открытых источников и ее аналитической обработки. При ведении КР все более
широкое применение находят новые направления науки и технологий, получившие
названия: "управление знаниями" (knowledge management) и
"обнаружение знаний в базах данных" (knowledge discovery in databases),
или Data и Text Mining (DM и TM) — глубинный анализ данных или текстов.
Если системы управления знаниями реализуют идею
сбора и накопления всей доступной информации как из
внутренних, так и из внешних источников, то технологии DM
и TM позволяют выявлять неочевидные закономерности в
данных или текстах — так называемые латентные (скрытые) знания. Системы этого
класса позволяют осуществлять анализ больших массивов документов и формировать
предметные указатели понятий и тем, освещенных в этих документах.
Характерная задача КР, обычно реализуемая в системах
TM, — это нахождение исключений, т.е. поиск объектов,
которые своими характеристиками сильно выделяются из общей массы. Еще один
класс важных задач, решаемых в рамках технологии TM,
— это моделирование данных, ситуационный и сценарный анализ, а также прогноз.
Для обработки и интерпретации результатов TM большое значение имеет визуализация. Часто
руководитель не всегда адекватно воспринимает предлагаемую ему аналитическую
информацию, особенно если она не вполне совпадает с его пониманием ситуации. В
связи с этим служба КР должна стремиться представлять информацию в виде,
адаптированном к индивидуальному восприятию заказчика.
При проведении КР отправной точкой считается не
информационный шум, а исследуемый объект. Поэтому хотя использование
информационного пространства Internet можно считать
очень перспективным, одновременно следует учитывать и слабые стороны Сети:
большой уровень недостоверности информации, неструктурированность
необходимых данных и, как следствие, сложность их поиска. Но в целом
возможности Internet оцениваются всеми экспертами в области
конкурентной КР достаточно высоко.
Первый лазер был
создан в 1960 году - и сразу началось бурное развитие лазерной техники. В
сравнительно короткое время появились различные типы лазеров и лазерных
устройств, предназначенных для решения конкретных научных и технических задач.
Для объяснения
этих свойств в научном языке есть специальный термин когерентность. Вполне
понятно, что поток света, распространяющийся от любого источника, есть
суммарный результат высвечивания великого множества элементарных излучателей,
каковыми являются отдельные атомы или молекулы светящегося тела. В случае лампы
накаливания каждый атом - излучатель высвечивается, никак не согласуясь с
другими атомами-излучателями, поэтому в целом получается световой поток,
который можно называть внутренне непорядочным, хаотическим. Это есть
некогерентный свет. В лазере же гигантское количество атомов излучателей
высвечивается согласованно, в результате возникает внутренне упорядоченный
световой поток. Это есть когерентный свет.
Когда мы говорим
о лазерном луче, то обычно представляем себе яркий и тонкий световой шнур или
световую нить. Нечто подобное можно увидеть в действительности
если включить гелий-неоновый лазер. Правда этот лазер
маломощный настолько, что его луч можно спокойно,, ловить,, в руку. К тому же
луч не,, ослепительно белый,, а сочного красного
цвета. Чтобы он был лучше виден, надо создать в лаборатории полумрак и легкую
задымленность. Луч почти не расширяется и везде имеет практически одинаковую
интенсивность. Можно размес-тить на его пути ряд
зеркал и заставить его описать. сложную
изломанную траекторию в пространстве лаборато-рии. В
результате возникнет эффективное зрелище - комната, как бы, перечеркнутая,, в разных направлениях яркими красными прямыми нитями.
Однако не всегда
лазерный луч выглядит столь эффектно. Например, луч СО2
лазера вообще невидим - ведь его длина волны попадает в инфракрасную область
спектра. Кроме того, не следует думать, что лазерный луч - это обязательные
непрерывный поток световой энергии. В большинстве случаев лазеры генерируют не
непрерывный световой пучок, а световые импульсы.
Анатомия лазера.
Как выглядит
лазер? На что он похож? Существует огромное число разных типов лазеров, они
различаются не только характеристиками генерируемого ими излучения, но также
внешним видом, размерами, особенностями конструкции.
” Сердце лазера”
- его активный элемент. У одних лазеров он представляет собой кристаллический
или стеклян-ный стержень
цилиндрической формы. У других это отпаянная стеклянная трубка, внутри которой
находится специально подобранная газовая смесь. У третьих - кювета со
специальной жидкостью. Соответственно различают лазеры твердотельные, газовые и
жидкостные.
Типы лазеров.
Газоразрядные
лазеры. Так называют лазеры на разряженных газовых смесях (давление смеси 1-10
мм рт. ст)
ко-торые возбуждаются самостоятельным электрическим
разрядом. Различают три группы газоразрядных лазеров: - лазеры, в которых
генерируемое излучение рождается на переходах между энергетическими уровнями
свободных ионов (применяется термин “ионные лазеры”).
- лазеры,
генерирующие на переходах между уровнями свободных атомов.
- лазеры,
генерирующие на переходах между уровнями молекул (так называемые молекулярные
лазеры) Из ог-ромного числа газоразрядных лазеров
выделим три: гелий-неоновый (как пример лазера, генерирующего на пе-реходах в атомах), аргоновый (ионовый
лазер) и СО2-лазер (молекулярный лазер) . (см. таблицы
113-115) Гелий -неоновой лазер имеет три основных рабочих перехода, на длинах
волн 3,39 и 1,15 и 0,63 мкм.
В аргоновом
лазере генерация происходит на переходах между уровнями однократного иона
аргона (Ar+) основными являются переходах на длинах
волн 0,488(голубой цвет) и 0,515 мкм (зеленый цвет).
Генерация в
СО2-лазере происходит на переходах между колебательными уровнями молекулы
углекислого газа (СО2) основными являются переходы на
длинах волн 9,6 и 10,6 мкм. Основными составляющими газовой смеси являются
углекислый газ и молекулярный азот.
Эксимерные лазеры. Так называют газовые лазеры, генерирующие на переходах между
электронными состояния-ми эксимерный
(разлетных) молекул. К таким молекулам
относятся, например молекулы Ar2, Kr2, Xe2, ArF, KrCl, XeBr и др. Эти молекулы
содержат атомы инертных газов.
Заметим, что в эксимерных лазерах реализованы наиболее низкие значения
генерируемых длин волн. Так. в
лазе-ре на молекулах Хе2 наблюдалась генерация на длине
волн 0,172 мкм, в лазере на молекулах Kr2 0,147 мкм, в лазере на Ar2 0,126 мкм.
Электроионизационные лазеры. В
качестве ионизирующего излучения используют ультрафиолетовое излучение,
электронный пучок из ускорителя, пучки заряженных частиц, являющихся продуктами
ядерных реакций.
Химические
лазеры. Реакции идущие с высвобождением энергии,
называют экзоэнергетичсекими. Они-то и представляют
интерес для химических лазеров. В этих лазерах, высвобождающаяся при химических
реакциях, идет на возбуждение активных центров и в
конечном счете преобразуется в энергию когерентного света.
ПРИМЕНЕНИЕ
ЛАЗЕРОВ В ВОЕННОМ ДЕЛЕ.
К настоящему
времени сложилась основные направления, по которым идет внедрение лазерной
техники в воен-ное дело.
Этими направлениями являются:
1. Лазерная
локация (наземная, бортовая, подводная) .2. Лазерная связь. 3. Лазерные
навигационные системы.
4. Лазерное
оружие. 5. Лазерные ситным ПРО и ПКО, создаваемые в рамках
стратегической оборонной инициа-тивы - СОИ.
Сейчас,
получены такие параметры излучения лазеров, которые способны существенно
повысить тактико-технические данные различных образцов военной аппаратуры
(стабильность частоты порядка 10 в -14, пиковая мощность 10 в -12 Вт, мощность
непрерывного излучения 10 в 4 Вт, угловой раствор луча 10 в -6 рад, t=10 в -12
с,... =0,2... 20 мкм.
ЛАЗЕРНАЯ
ЛОКАЦИЯ.
Лазерной
локацией называют область оптикоэлектроники,
занимающегося обнаружением и определением местоположения различных объектов при
помощи электромагнитных волн оптического диапазона, излучаемого лазе-рами. Объектами лазерной
локации могут быть танки, корабли, ракеты, спутники, промышленные и военные
сооружения. Принципиально лазерная локация осуществляется активным методом. Нам
уже известно, что лазерное излучение отличается от температурного
тем, что оно является узконаправленным, монохроматичным,
имеет большую импульсивную мощность и высокую спектральную яркость. Все это
делает оптическую локацию конкурентоспособной в сравнении с радиолокаций,
особенно при ее использовании в космосе (где нет поглощающего воздействия
атмосферы) и под водой (где для ряда волн оптического диапазона существуют окна
прозрачности).
НАЗЕМНЫЕ
ЛАЗЕРНЫЕ ДАЛЬНОМЕРЫ.
Лазерная дальнометрия является одной из первых областей
практического применения лазеров в зарубежной военной технике. Первые опыты
относятся к 1961 году, а сейчас лазерные дальномеры используются и в наземной
военной технике(артиллерийские, таковые), и в авиации
(дальномеры, высотомеры, целеуказатели), и на флоте.
Эта техника прошла боевые испытания во Вьетнаме и на Ближнем Востоке. В
настоящее время ряд дальномеров принят на вооружение во многих армиях мира.
Задача
определения расстояния между дальномером и целью сводится к измерению
соответствующего интервала времени между зондирующим сигналом и сигналом,
отражения от цели. Различают три метода измерения дальности в зависимости от
того, какой характер модуляции лазерного излучения используется в дальномере:
импульсный, фазовый или фазово-импульсный. Внешний вид импульсного дальномера
показан на рисунке.
21.
Классификация методов извлечения знаний.
1. Коммуникативные
– этот класс объединяет методы в/д эксперта и
системного аналитика;
2. Текстологические
методы – определяют процедуру извлечения знаний из текстовых источников.
Коммуникативные методы по роли системных
аналитиков разделяют на 2 группы: активные и пассивные.
В пассивных – системный аналитик лишь фиксирует
протоколы сеансов извлечения знаний, не влияя на эксперта. При этом ведущая
роль у эксперта.
В активных – ведущая роль отводится системному аналитику,
который управляет сценарием диалога с экспертом
и существует обратная связь. Эксперт является лишь источником знаний.
Активные методы
разделяются на групповые и индивидуальные. На практике
комбинируют различные методы в зависимости от ситуации, характеристик личности
эксперта, системного аналитика и степени документирования предметной области.
Главная цель – сформировать
наиболее точную и полную картину предметной области для последующего
кодирования в БЗ.
Классификацией
людей по психологическим характеристикам является «классификация по уровню
сознания». Выделяют 3 типа людей:
1. мыслители –
люди, ориентированные на интеллектуальную работу. Предпочитают работать с
книгами, статьями, а не человеком.
2. собеседник –
люди, предпочитающие диалог, нежели работу с литературой.
3. прагматики –
люди, предпочитающие действия рассуждениям. Хорошо реализуют замыслы других.
Любая предметная
область имеет структуру знаний, сформированную в какой-либо науке. Выделяют 3
типа областей:
1. хорошо
документированная, где существует единая теория, описывающая объекты, процессы
и явления с помощью формальных моделей, и установлены в/связи м/ними, и используется общепринятая терминология.
2. средне
документированная. Здесь определена терминология, развивается единая теория и
установлены основные взаимосвязи.
3. слабо
документированная. Здесь нет теории, есть гипотезы. Есть большой V эмпирических данных.