МИР
Оглавление
2
Классификация мировых информационных ресурсов по секторам информации
5.
Визуализация многомерных данных.
6.
Модели данных для индексации текстовых и графических информационных ресурсов.
7.
Релевантность и критерий выдачи документов в основных моделях поиска.
1 Основные понятия: информационные ресурсы, документ, информация, сведения, данные, формат данных, структура данных.
Информационные ресурсы – это отдельные документы, массивы документов, которые
входят в состав информационных систем.
Документ – это материальный объект с зафиксированной на нем
информацией, предназначенный для
передачи во времени и пространстве в целях хранения и общественного
использования.
Сведения - это набор сигналов физических процессов
воспринимаемых субъектом через органы его чувств. (Субъектом может быть человек
или машина, которая предназначена для восприятия сигналов).
Cведения, полученные путём измерения, наблюдения,
логических или арифметических операций представленные в форме, пригодной для
хранения, передачи и обработки называются данными.
Данные
различаются по:
1.
Формату данных – характеристика
данных, способствующая оптимальному их использованию
и определяющая структуру и способ их
хранения, диапазон возможных значений и допустимые операции, которые
можно выполнять над этими данными. (Графический документ, электронный формат и
т.д.)
2.
Структуре данных – это
организационная схема, в соответствии с которой данные упорядочены с тем, чтобы
их можно было максимально эффективно интерпретировать или выполнять над ними различные
операции.
Виды данных:
Реляционные
данные - это данные из реляционных
баз (таблиц).
Многомерные
данные - это данные, представленные в
многомерных кубах OLAP.
Измерение
(dimension) или ось - в многомерных данных - это собрание данных одного и того же типа.
Измерения позволяют структурировать многомерную базу данных.
По
критерию постоянства своих значений в ходе решения задачи данные могут быть: переменными;
постоянными; условно-постоянными.
Переменные
данные - это такие данные, которые
изменяют свои значения в процессе решения задачи.
Постоянные
данные - это такие данные, которые
сохраняют свои значения в процессе решения задачи (математические константы, координаты
неподвижных объектов) и не зависят от внешних факторов.
Условно-постоянные
данные - это такие данные, которые
могут иногда изменять свои значения, но эти изменения не зависят от процесса
решения задачи, а определяются внешними факторами.
Данные,
в зависимости от тех функций, которые они выполняют, могут быть справочными,
оперативными, архивными.
Следует
различать данные за период и точечные данные.
Данные за
период характеризуют некоторый период
времени. Примером данных за период могут быть: прибыль предприятия за
месяц, средняя температура за месяц.
Точечные
данные представляют значение
некоторой переменной в конкретный момент времени. Пример точечных данных:
остаток на счете на первое число месяца, температура в восемь часов утра.
Данные
бывают первичными и вторичными (агрегированными).
Вторичные
данные - это данные, которые являются
результатом определенных вычислений, примененных к первичным данным.
Вторичные данные, как правило, приводят к ускоренному получению ответа на
запрос пользователя за счет увеличения объема хранимой информации.
Метаданные
(Metadate) - это данные о данных.
В
состав метаданных могут входить: каталоги, справочники, реестры.
Метаданные
содержат сведения о составе данных, содержании, статусе, происхождении,
местонахождении, качестве, форматах и формах представления, условиях доступа,
приобретения и использования, авторских, имущественных и смежных с ними правах
на данные и др.
2 Классификация мировых информационных ресурсов по секторам информации
Мировые
информационные ресурсы обычно подразделяются на три сектора:
-
сектор деловой
информации;
-
сектор
научно-технической и специальной информации;
-
сектор массовой
потребительской информации.
Сектор
деловой информации подразделяется на группы:
1. Биржевая и финансовая информация. Эта информация о
котировках ценных бумаг, валютных курсах, учетных ставках, рынках товаров и
капиталов. Информация предоставляется биржами, брокерскими компаниями и
специальными службами финансовой информации.
2. Статистическая информация:
-
числовая;
-
экономическая;
-
демографическая;
-
социальная.
Эта
информация представляется в виде прогнозов, моделей, рядов динамики государственными
службами и компаниями, занятыми исследованиями, разработками и консалтингом.
3. Коммерческая информация. Это информация по компаниям,
фирмам, корпорациям, направлениям их работы, финансовым состоянием, ценам на
продукцию и услуги, связи, сделки и руководителям.
4. Деловые новости в области экономики и бизнеса.
Коммерческая информация используется предпринимателями при решении следующих
задач:
-
выбор
поставщиков, партнеров и размещение заказов;
-
при выходе на
рынок с новым товаром;
-
при поиске
покупателей;
-
при слиянии и
приобретении компании;
-
при маркетинговых
исследованиях по анализу рынка.
Сектор
научно-технической и специальной информации включает: документальную, библиографическую,
реферативную и полнотекстовую информацию о фундаментальных и прикладных
исследованиях и профессиональную информацию для юристов, врачей, инженеров и
остальных групп.
Сектор
массовой потребительской информации включает новости и справочную информацию,
потребительскую развлекательную информацию.
Классификация Web ресурсов
Web ресурсы (сайты) классифицируются на 2 группы:
навигационные сайты (перенаправляют
пользователей к конечным сайтам) и конечные (функциональные) сайты (содержат
информацию или документы, которые необходимы пользователям).
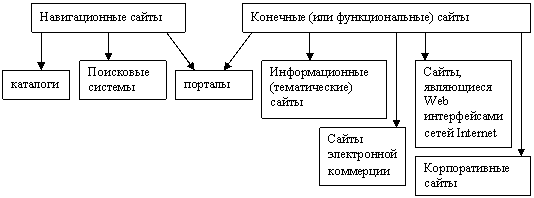
Портал – это Web сайт,
сочетающий в себе функции навигационного сайта
и информационного ресурса по различным темам.
Информационные
сайты
- обеспечивают доступ пользователей к документам определенной тематики.
Корпоративные
сайты, а так же сайты электронной коммерции
– дают доступ к коммерческой информации (информации о товарах, услугах, производителях), а также возможность
удаленного заказа, оплаты и приобретения товаров и услуг.
Web интерфейс – это сайты, которые через стандартные Web страницы предоставляют доступ к сервисам Internet (электронной почты, телеконференций и другим).
3. Организация поиска информации в мировой сети. Поисковые машины и каталоги. Модели поиска информации
Существует
два вида информационных баз данных о web-страницах:
поисковые машины и каталоги.
Поисковые машины: (spiders, crawlers) постоянно исследуют Сеть с целью
пополнения своих баз данных документов. Обычно это не требует никаких усилий со
стороны человека. Для поисковых систем довольно важна конструкция каждого
документа. Большое значение имеют title, meta-таги и содержимое страницы.
Каталоги: в отличие от поисковых машин в каталог информация
заносится по инициативе человека. Добавляемая страница должна быть жестко
привязана к принятым в каталоге категориям. Конструкция страниц значения не
имеет.
Модели
поиска информации
Булева модель поиска является классической и широко используемой моделью
информационного поиска, базирующейся на математической логике. В рамках булевой
модели документы и запросы представляются в виде множества морфемных основ ключевых
слов (термов). В булевой модели запрос пользователя представляет собой логическое
выражение, в котором ключевые слова (термы запроса) связаны логическими операторами
AND (в результаты поиска включаются только те документы, которые содержат
одновременно все ключевые слова запроса), OR (в результаты поиска включаются
документы, в которые входит хотя бы одно из ключевых слов запроса) и NOT.
БД
информационно-поисковых систем состоит из след. осн-х таблиц:
- текстовой,
содержащей текстовую часть всех документов;
- таблицы
указателей текстов, включающей указатели местонахождения документов в текстовой
таблице, а заодно и форматные поля всех документов;
- словарной,
содержащей все уникальные слова, встречающиеся в полях документов, т.е. те
слова, по которым может осуществляться поиск. Слова могут быть связаны в синонимические
цепочки;
- инверсной,
содержащей списки номеров документов и координаты всех вхождений отдельных слов
в полях документов.
Поиск
термина в базе данных осуществляется следующим образом.
1.
Происходит обращение к словарной таблице, по которой определяется, входит ли слово
в состав словаря БД, и если входит, то определяется ссылка на цепочку появлений
этого слова в документах.
2.
Выполняется обращение к инверсной таблице, по которой определяются координаты
всех вхождений терма в текстовую таблицу базы данных.
3.
По номеру документа происходит обращение к записи таблицы указателей текстов. Каждая
запись этого файла соответствует одному документу в базе данных.
4.
По номеру документа осуществляется прямое обращение к фрагменту текстовой таблицы
— документу — и последующий его вывод.
5.
В случае, когда обрабатывается выражение, состоящее не из одного слова, а из
некоторого словосочетания, в результате отработки поиска по каждому слову
запроса формируется массив записей, соответствующих вхождению этого термина в
базу данных. После окончания формирования массивов результатов поиска
происходит выявление релевантных документов путем выполнения
теоретико-множественных операций над записями этих массивов.
Векторно-пространственная модель
Большинство
известных информационно-поисковых систем и систем классификации информации в той
или иной мере основываются на использовании векторной модели описания данных.
Векторная модель является классической алгебраической моделью. В рамках этой
модели документ описывается вектором, в котором каждому используемому в документе
терму ставится в соответствие его весовой коэффициент (значимость), который определяется
на основе статистической информации о его вхождении в отдельном документе или в
документальном массиве. Описание запроса, который соответствует необходимой
пользователю тематике, также представляет собой вектор в том же евклидовом
пространстве термов. В результате для оценки близости запроса и документа
используется скалярное произведение соответствующих векторов описания тематики
и документа.
Один
из возможных простейших подходов — использовать в качестве веса терма в документе
нормализованную частоту его использования в данном документе.
Гибридные модели поиска
На
практике чаще всего используются гибридные подходы, в которых объединены возможности
булевой и векторно-пространственной моделей и зачастую добавлены оригинальные
методы семантической обработки информации. Чаще всего в информационно-поисковых
системах процедура поиска выполняется в соответствии с булевой моделью, а
результаты ранжируются по весам в соответствии с моделью векторного пространства.
4. Организация хранения данных: данные в реляционных хранилищах, многомерное хранение данных, хранилища данных. Компоненты хранилищ данных
Для
адекватного представления предметной области, простоты разработки и поддержания
базы данных отношения должны быть приведены к третьей нормальной, то есть быть
сильно нормализованными. Однако слабо нормализованные отношения также имеют
свои достоинства, основным из которых является то, что если к базе данных обращаться
в основном только с запросами, а модификации и добавление данных проводить
очень редко, то их выборка производится значительно быстрее.
Сильно
нормализованные модели данных хорошо подходят для OLTP-приложений – On-Line Transaction Processing (OLTP) –
приложений оперативной обработки транзакций (системы складского учета, заказов
билетов).
OLAP - это On-Line
Analitical Processing (оперативный анализ данных). OLAP-приложения
– приложения оперативной аналитической обработки данных. Это обобщенный
термин, характеризующий принципы построения систем поддержки принятия решений –
Decision Support System (DSS), хранилищ данных – Data Warehouse,
систем интеллектуального анализа данных – Data Mining.
Хранилища данных – это предметно-ориентированное, привязанное ко
времени и неизменяемое собрание данных для поддержки процесса принятия
управляющих решений.
Хранилищам
данных свойственны следующие черты.
Предметная ориентированность. Информация в
хранилище организована в соответствии с основными аспектами деятельности
предприятия (заказчики, продажи, склад и т. п.); это отличает хранилище данных
от оперативной БД, где данные организованы в соответствии с процессами (выписка
счетов, отгрузка товара и т. п.).
Интегрированность. Семантически
одни и те же данные в разных базах могут быть выражены в разных единицах
измерения. При загрузке в хранилище данные должны быть проверены, очищены и
приведены к единому виду. Анализировать такие интегрированные данные намного
проще.
Привязка ко времени. Данные, выбранные их оперативных БД, накапливаются в
хранилище в виде «исторических слоев», каждый из которых относится к
конкретному периоду времени. Это позволяет анализировать тенденции в развитии
бизнеса.
Неизменяемость. Попав в хранилище, данные «залегают» в свой
«исторический слой» и уже никогда не меняются. Это еще одно отличие хранилища
от оперативной БД. Стабильность данных облегчает их анализ.
Основные
компоненты
Основные
компоненты хранилища данных таковы: оперативные источники данных; средства
переноса и трансформации данных; метаданные; реляционное хранилище;
OLAP-хранилище; средства доступа и анализа данных.
Рассмотрим
основные потоки данных в хранилище. Оперативные данные собираются из различных
источников, очищаются, интегрируются и складываются в реляционное хранилище.
При этом они уже доступны для анализа при помощи средств построения отчетов.
Затем данные (полностью или частично) подготавливаются для OLAP-анализа. При
этом они могут быть загружены в специальную БД OLAP или оставаться в реляционном
хранилище. Важнейшим элементом хранилища являются метаданные, т. е. данные о
структуре, размещении, трансформации данных. Чтобы эффективно взаимодействовать,
различные компоненты хранилища должны уметь использовать общие метаданные.
Структуры данных в хранилище
Структуры
данных хранилища заметно отличаются от применяемых в OLTP-системах. Это в
первую очередь определяется предметной ориентированностью хранилища: данные
организованы вокруг того или иного аспекта деятельности предприятия. Типичными
структурами, применяемыми в хранилищах данных, являются схемы звезды и снежинки.
Схема
звезды довольно проста. Она состоит
из одной таблицы фактов (fact table) и нескольких таблиц измерений (dimension
table). Таблица фактов содержит по одной строке для каждого факта - минимально
рассматриваемого атома анализируемого процесса. Полями таблицы фактов, помимо
ключей, являются меры (measures). Для процесса продаж фактами могут быть
продажи отдельных товаров (партий товаров, вагонов и т. п. - детальность
таблицы фактов выбирается в зависимости от разных факторов).
Схема
снежинки является модификацией схемы
звезды, как бы уступкой нормализации - здесь часть таблиц измерений разбита
несколько связанных таблиц. Можно сказать, что она получена из схемы звезды
путем выделения в отдельные таблицы Класса Продукта (таблица product_class) и
Региона (таблица region).
Благодаря
частичной нормализации, «снежинка» позволяет сэкономить дисковое пространство,
но она также дает еще одно преимущество - увеличивается скорость просмотра измерений.
5. Визуализация многомерных данных.
Многомерное
представление данных: куб
OLAP
предоставляет удобные быстродействующие средства доступа, просмотра и анализа
деловой информации. Пользователь получает естественную, интуитивно понятную модель
данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы
координат служат основные атрибуты анализируемого бизнес-процесса. Например,
для продаж это могут быть товар, регион, тип покупателя. В качестве одного из
измерений используется время. На пересечениях осей - измерений (Dimensions) -
находятся данные, количественно характеризующие процесс - меры (Measures). Это
могут быть объемы продаж в штуках или в денежном выражении, остатки на складе,
издержки и т. п. Пользователь, анализирующий информацию, может
"разрезать" куб по разным направлениям, получать сводные (например,
по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие
манипуляции, которые ему придут в голову в процессе анализа.
“Разрезание” многомерного куба
В качестве
мер в трехмерном кубе использованы суммы продаж, а в качестве измерений -
время, товар и магазин. Измерения представлены на определенных уровнях группировки:
товары группируются по категориям, магазины - по странам, а данные о времени совершения
операций - по месяцам. Чуть позже мы рассмотрим уровни группировки (иерархии)
подробнее.
Для
визуализации данных, хранящихся в кубе, применяются, как правило, привычные
двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки
строк и столбцов.
Двумерное
представление куба можно получить, "разрезав" его поперек одной или нескольких
осей (измерений): мы фиксируем значения всех измерений, кроме двух, - и получаем
обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов)
представлено одно измерение, в вертикальной (заголовки строк) - другое, а в ячейках
таблицы - значения мер. При этом набор мер фактически рассматривается как одно
из измерений - мы либо выбираем для показа одну меру (и тогда можем разместить
в заголовках строк и столбцов два измерения), либо показываем несколько мер (и
тогда одну из осей таблицы займут названия мер, а другую - значения
единственного "неразрезанного" измерения).